Digital-CIM 使用规范
Deprecated
本文档已废弃,仅用于历史参考。当前项目已无法访问该 Digital-CIM IP(DCIM IP)。
1. 概述
CIM 是 Compute-in-Memory 的缩写,即存内计算。 Digital-CIM (DCIM) 使用标准 SRAM 单元实现存储,并在 SRAM 阵列中添加或非门和加法器树实现乘累加操作。 DCIM 天然实现了 Weight Stationary,并且内存和计算单元是紧密集成在一起的,这种紧密集成的设计可以减少数据传输的时间和功耗,提高计算效率。
CIM 的功能可以大致分为三类:
- 存储:将权重存储在 CIM 的存储单元中
- 读权重:将存储的数据读出
- 计算:将输入特征和权重相乘累加
2. 规模
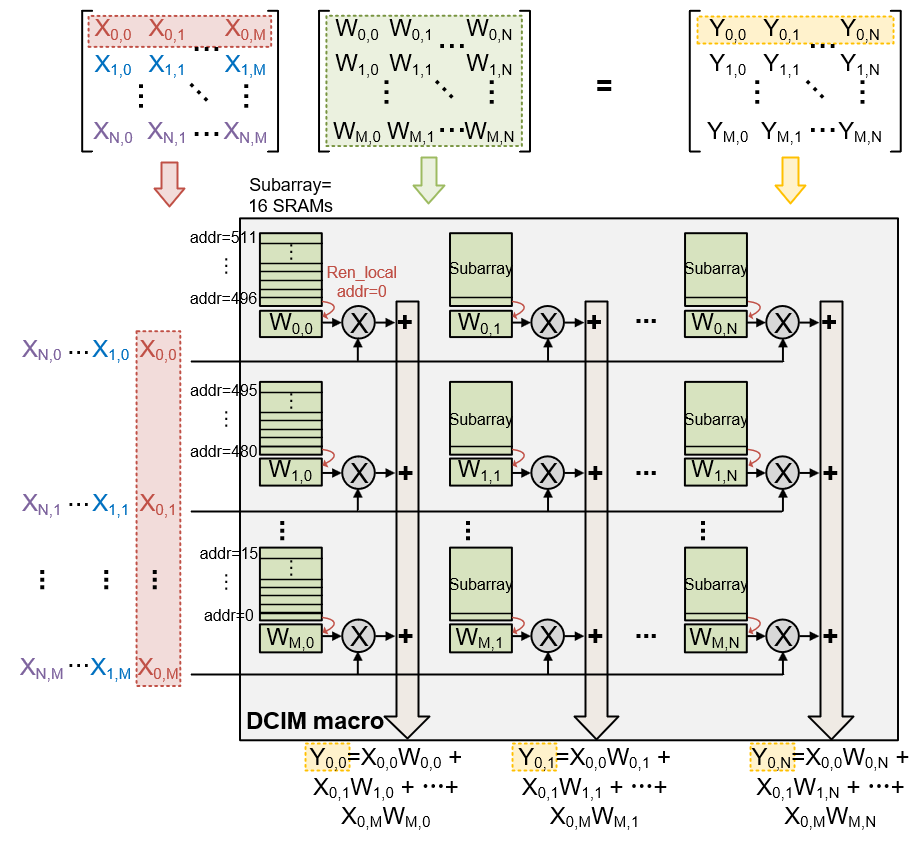
DCIM 的规模为 512 行 x 256 列。 对于一列中的 512 个 SRAM 单元,每 16 个 SRAM 单元构成一个 subarray,一共有 32 个 subarray。
每个 SRAM 单元通过或非门完成权重与输入的 1-bit 乘法,再通过 32 个 subarray 之间的加法器树完成累加。
DCIM 计算实例
假设 CIM 规模为 1 列 512 个 SRAM 单元,每个 subarray 中 16 个 SRAM 单元(一共 32 个 subarray),需要计算无符号数 a_0[3:0] \times w_0[3:0] + a_1[3:0] \times w_1[3:0] + ... + a_{127}[3:0] \times w_{127}[3:0]。
首先,CIM 会将 w_x 按照如下顺序依次存储在 32 个 subarray 中:
- subarray 0: w_0[3:0],\ w_1[3:0],\ w_2[3:0],\ w_3[3:0]
- subarray 1: w_4[3:0],\ w_5[3:0],\ w_6[3:0],\ w_7[3:0]
- ...
- subarray 31: w_{124}[3:0],\ w_{125}[3:0],\ w_{126}[3:0],\ w_{127}[3:0]
接下来,CIM 会按照 bit-serial 的顺序输入 4-bit 数。
- 第一轮输入:\{a_0[3], a_4[3], ..., a_{124}[3]\}
- 第二轮输入:\{a_0[2], a_4[2], ..., a_{124}[2]\}
- 第三轮输入:\{a_0[1], a_4[1], ..., a_{124}[1]\}
- 第四轮输入:\{a_0[0], a_4[0], ..., a_{124}[0]\}
然后,DCIM 需要通过地址的最低 4 位来切换 subarray 中的权重,同时切换对应的输入。
数据流
上述实例只是 DCIM 的一种数据流,可以有多种不同的映射方式。
3. 端口列表
| 端口 | 方向 | 描述 |
|---|---|---|
| CLK | input | 时钟 |
| WEN | input | 写使能,高电平触发 |
| REN_GLOBAL | input | 读使能,高电平触发,读一整行 |
| REN_LOCAL | input | 读使能,高电平触发,读 local buffer |
| ADDR[9:0] | input | 地址 |
| EMA_RSA[1:0] | input | trim,默认全 1 |
| EMA_RWL[1:0] | input | trim,默认全 1 |
| MASK[63:0] | input | 写入掩码,1 为写入,粒度为 4-bit |
| SIGN[3:0] | input | INT4: 1111, INT8: 1010, INT16: 1000 |
| D[255:0] | input | 写权重数据 |
| Q[255:0] | output | 读权重数据 |
| IFN[31:0] | input | 计算输入(取反) |
| PSUM[575:0] | output | 计算输出 |
trim 信号
"Trim" 信号通常与工艺补偿和性能优化有关。 它用于在制造过程中或之后对芯片的电气特性进行微调。 这可以包括调整电压、电流或其他参数,以确保芯片在各种条件下都能正常工作。 Trim 信号的使用有助于提高芯片的良率和性能一致性。
4. DCIM IP 路径
服务器上经过流片验证的 DCIM IP 路径为:

特别感谢 Wenjie Ren,Yifan Ding 对本页内容的贡献和校对!