C 代码编译
阅读建议
如果你不想了解编译原理,只想获得工具链和一个编译模板以便开发测试代码,可以直接跳到 2. 安装 RISC-V Toolchain。 但我们建议你阅读整个章节,以便更好地理解编译的过程。
1. 编译流程
我们需要知道软件代码如何翻译成 CPU 可运行的指令,这个过程被称为编译(Compilation)。 将 C 程序翻译成计算机可运行的机器语言程序需要四个经典步骤:
foo.c -- Compiler --> foo.s -- Assembler --> foo.o -- Linker --> a.out -- Loader --> CPU
Note
这些步骤是概念上的,实际上会合并某些步骤来加速翻译过程。
1.1 Compiler & Assembler
编译器负责将高级语言转换成汇编,汇编器负责将汇编转换成机器码。
汇编器的作用不仅是用处理器可理解的指令生成目标代码,还支持一些对汇编语言程序员或编译器开发者有用的操作。
这类操作是常规指令的巧妙特例,称为伪指令。
最经典的例子为 nop,它在 RISC-V 中由 addi x0, x0, 0 实现。
Note
在程序员视角下,32 个 GPR 有不同于 x0 ~ x31 的名称,这被称为 ABI (Application Binary Interface)。
下面是一段汇编
.text # 指示符:进入代码节
.align 2 # 指示符:将代码按 2^2 字节对齐
.globl main # 指示符:声明全局符号 main
main: # main 的开始符号
addi sp,sp,-16 # 分配栈帧
sw ra,12(sp) # 保存返回地址
lui a0,%hi(string1) # 计算 string1
addi a0,a0,%lo(string1) # 的地址
lui a1,%hi(string2) # 计算 string2
addi a1,a1,%lo(string2) # 的地址
call printf # 调用 printf 函数
lw ra,12(sp) # 恢复返回地址
addi sp,sp,16 # 释放栈帧
li a0,0 # 装入返回值 0
ret # 返回
.section .rodata # 指示符:进入只读数据节
.balign 4 # 指示符:将数据按 4 字节对齐
string1: # 第一个字符串符号
.string "Hello, %s!\n" # 指示符:以空字符结尾的字符串
string2: # 第二个字符串符号
.string "world" # 指示符:以空字符结尾的字符串
以英文句号开头的命令称为汇编器指示符(Assembler directives)。 这些命令作用于汇编器,而非由其翻译的代码,具体用于通知汇编器在何处放置代码和数据、指定程序中使用的代码和数据常量等。
Note
汇编器生成的文件为 ELF(Executable and Linkable Format,可执行可链接格式)[TIS Committee 1995] 标准格式目标文件。
1.2 Linker
链接器允许分别编译和汇编各文件,故只改动一个文件时无需重新编译所有源代码。
链接器把新目标代码和已有机器语言模块(如函数库)“拼接” 起来,即编辑目标文件中所有 “跳转并链接(jal)” 指令的链接目标。
例如上述汇编有两个数据符号(string1 和 string2)和两个代码符号(main 和 printf)待确定。
根据链接的形式,可以将链接结果分为静态(static linking)和动态(dynamic linking)两种。 前者在程序运行前链接并加载所有库的代码,后者首次调用所需外部函数时才会将其加载并链接到程序中。
在编译和链接程序的过程中,通常会链接标准库和启动文件。 标准库(Standard Library)包含了许多常用的函数,例如输入输出函数、字符串处理函数等。 大多数程序都会使用到标准库中的函数,因此在链接阶段,编译器会将这些函数的代码链接到生成的可执行文件中。
启动文件(Start Files)是一些特殊的对象文件,它们包含了程序启动时需要执行的一些初始化代码。
例如,C 程序的入口点实际上是一个名为 start 或 _start 的函数,这个函数在启动文件中定义,它会设置好运行环境后再调用 main 函数。
具体的启动文件取决于你的编译器和操作系统。
例如,在使用 GCC 编译器的 Linux 系统中,启动文件通常是 crt1.o、crti.o、crtbegin.o、crtend.o 和 crtn.o。
这些文件中的代码会设置堆栈,初始化全局变量,调用全局构造函数,等等。
Note
当编译器选项中包含 -nostdlib 和 -nostartfiles 时,表示在链接阶段不链接标准库和启动文件。
这通常在编写操作系统或嵌入式系统的代码时使用,因为这些系统可能没有标准库,或者需要自定义启动过程。
需要注意的是,-nostdlib 选项不仅会禁止链接 C 标准库,还会禁止链接启动文件和 GCC 的运行时库。
如果你只想禁止链接 C 标准库,但仍然需要链接启动文件和 GCC 的运行时库,你可以使用 -nodefaultlibs 选项。
对象文件(.o 文件)是编译器生成的中间文件,它包含了源代码编译后的机器代码,但还没有被链接成可以执行的程序。 这些文件通常包含二进制数据,以及一些元数据,如符号表、重定位信息等。符号表中记录了源代码中的函数和变量的名称(符号)以及它们在机器代码中的位置。 重定位信息用于在链接阶段确定符号的最终地址。
Note
你可以使用一些工具来查看对象文件的内容。
例如,你可以使用 objdump 工具来反汇编对象文件,查看它的汇编代码。你也可以使用 nm 工具来查看对象文件中的符号表。
查看反汇编代码: objdump -d foo.o;
查看符号表: objdump -t your_file.o;
查看重定位信息:objdump -r your_file.o。
1.3 Loader
运行一个程序时,加载器会将其加载到内存中,并跳转到它的起始地址。
可执行文件可以接收命令行参数。这些参数在程序启动时通过 main 函数的参数传递给程序。
main 函数的原型为 int main(argc, *argv[])。
其中,argc 是命令行参数的数量,argv 是一个指向字符指针数组的指针,该数组包含了所有的命令行参数。
argv[0] 是程序的名称,argv[1] 是第一个命令行参数,以此类推。
最后一个元素 argv[argc] 是一个空指针。
例如,如果你的程序名为 prog,并且你通过以下方式启动它:./prog arg1 arg2,那么 argc 将为 3,argv[0] 将为 ./prog,argv[1] 将为 arg1,argv[2] 将为 arg2。
Info
如今的 “加载器” 就是操作系统。
Note
在进行交叉编译时,你的主机上的库(包括 C 标准库)通常不能直接用于目标系统。 这是因为主机和目标系统可能有不同的架构(例如,主机可能是 x86,而目标系统是 RISC-V),并且它们可能有不同的操作系统接口(例如,主机可能是 Linux,而目标系统是 bare-metal)。
因此,当你在 bare-metal RISC-V 环境中编译程序时,你需要一个为 RISC-V 架构和 bare-metal 环境定制的 C 库。
这个库应该包含适合你的目标环境的函数实现,包括 exit 函数。
如果你的程序使用了 C 库中的 exit 函数,但你没有提供一个适合你的目标环境的 exit 函数实现,那么在链接阶段,链接器会报错,因为它找不到 exit 函数的定义。
Tip
你可以查询 RISC-V Assembly Programmer's Manual 来了解如何编写 RISC-V 汇编语言。
2. 安装 RISC-V Toolchain
Warning
需要在 WSL 环境中安装! WSL 的安装以及网络配置请参考 WSL。
从 GitHub 上下载 RISC-V 工具链源码并进入该目录:
安装依赖:
sudo apt-get install autoconf automake autotools-dev curl git libmpc-dev libmpfr-dev libgmp-dev gawk build-essential bison flex texinfo gperf libtool bc zlib1g-dev
(可选)配置 CPU 核数以便多线程编译:
如何查看 CPU 核数
WSL:
在 Terminal 中输入:
Windows:打开任务管理器,左栏中选择“性能”选项卡,右下角即可看到 CPU 核数(逻辑处理器)。
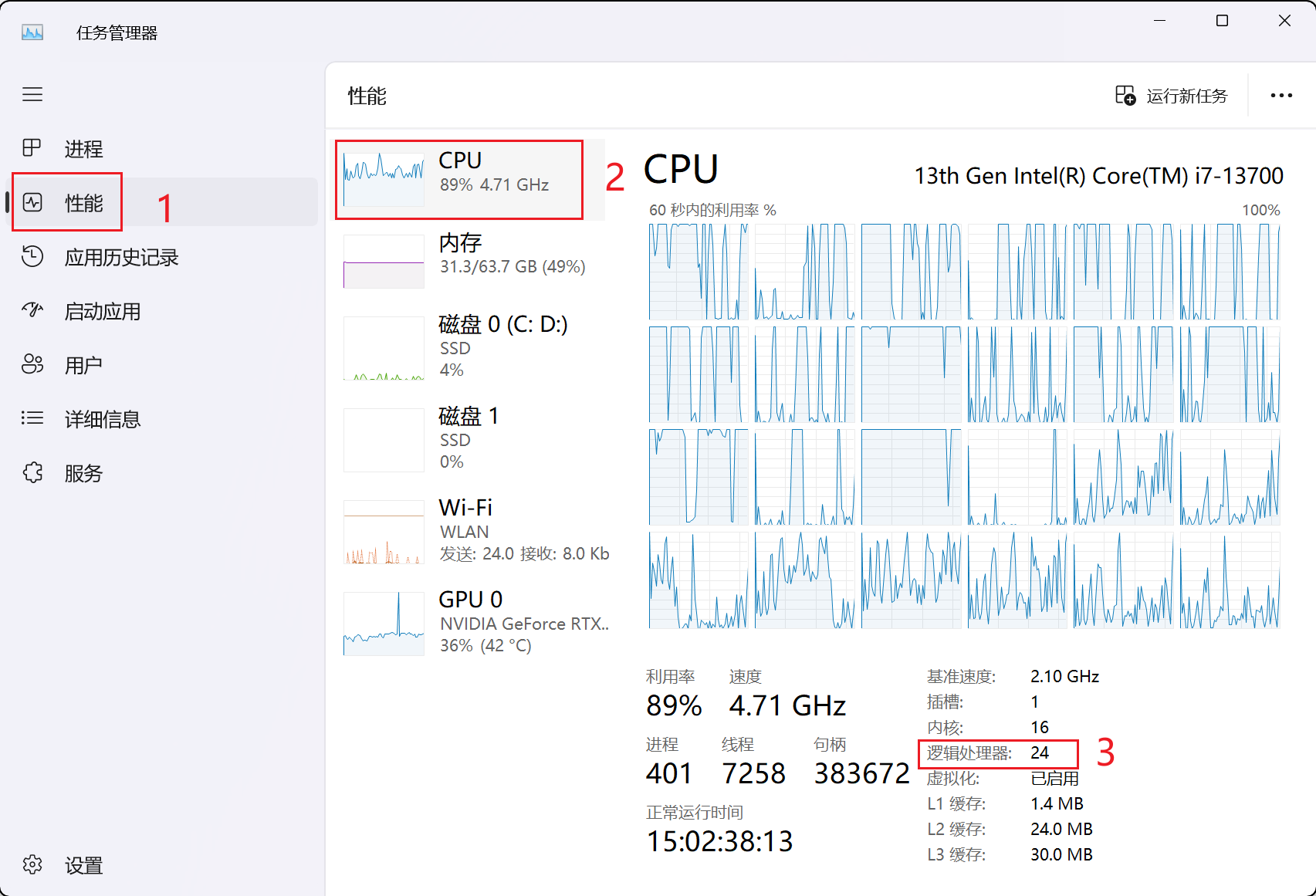
逻辑处理器与内核的区别:
- 内核:CPU 的物理核心数
- 逻辑处理器:CPU 的线程数,例如单个物理 CPU 内核支持双线程,则 2 个这样内核的逻辑处理器数为 4。
配置工具链安装路径:
执行脚本安装工具链:
# Fetch the source code of the toolchain (assumes Internet access.)
sh get-toolchain.sh
# Build and install the toolchain (requires write+create permissions for $RISCV.)
sh build-toolchain.sh $RISCV
安装完成后,$RISCV/bin 目录下会有 RISC-V 工具链的可执行文件(例如 riscv-none-elf-gcc、riscv-none-elf-gdb)。
3. 编译模板
从 GitHub 上下载一个简单的 C 代码模板,用于编译 RISC-V 汇编代码。
设置环境变量,指定 RISC-V 工具链路径。
export RISCV_GCC=<riscv-gcc-toolchain>/bin/riscv-none-elf-gcc
export RISCV_OBJDUMP=<riscv-gcc-toolchain>/bin/riscv-none-elf-objdump
修改 C 文件,按需修改汇编代码。
然后执行 make 编译。
Makefile 会生成如下两个文件:
*.o:编译后的目标文件,用于 GDB 的load指令。*.asmm:反汇编后的文件,用于查看编译结果。*.hex:使用asm2hex.py脚本生成的十六进制内存初始化文件,用于仿真。
关于反汇编结果
如果你查看过反汇编结果,你会发现反汇编后的代码和源代码有些不同。
具体来说,反汇编后的代码的开头和结尾会有一些额外的指令,这些指令都与 sp 寄存器相关。
sp 寄存器是栈指针寄存器,用于指向当前栈顶的地址。
C 代码中的函数调用会使用栈来保存函数的返回地址、参数和局部变量。
因此,函数的编译结果包括三个部分:函数的栈分配、函数的代码、函数的栈释放。
关于静态数组与动态数组
在嵌入式 RISC-V 平台上编译 C 程序时,数组大小的不同可能会导致编译器生成不同的代码,进而影响程序的行为。
特别是当数组的大小超过一定阈值时,编译器可能会选择使用库函数(如 memcpy)来初始化或复制数组。
嵌入式环境中通常不使用标准 C 库(如 libc),因为这些库可能依赖于操作系统提供的功能。
在使用 -nostdlib 选项时,你的程序不会链接标准 C 库,因此如果编译器自动生成了对 memcpy 的调用,而你没有提供 memcpy 的实现,就会导致链接错误。
为了避免这种情况,我们可以使用静态数组(static),这样编译器就会在编译时将数组的大小固定下来,而不会使用库函数。
编译器会将数组的内容直接放入 .data 段(如果是可修改的)或 .rodata 段(如果是只读的)。
与静态数组相对应的是动态数组(dynamic),它的大小是在运行时确定的,因此编译器无法在编译时将数组的大小固定下来,通常使用动态内存分配函数(如 malloc)来在堆(heap)中分配内存。
关于.rodata字段
如果将 .rodata 段放置在 RAM 中,并且没有任何硬件或软件保护措施,那么这些数据实际上是可修改的,不再具有只读属性。
保持 .rodata 只读属性:
- 确保
.rodata段放在只读存储器中(如 Flash/ROM)。 - 如果必须放在 RAM 中,使用 MMU 或类似的机制来施加只读保护。
- 在没有硬件支持的嵌入式系统中,依赖编程约定来保证
.rodata不被修改。
4. 数据加载到指定地址
在测试流程中,我们可能需要将数据加载到特定的内存地址,例如指令基地址为 0x8000_0000,时钟配置寄存器基地址为 0x2000_0000 等。 最直观、简单的加载数据方式为:在 C 代码中显式地定义地址指针,并对该地址进行赋值。
上述方法会导致数据被存储了两份:一份在编译出来的目标文件中,另一份在运行时被写入到指定地址。
如果我们只想存储一份数据,可以定义一个静态数组,并在编译时通过链接器脚本 linker.ld 将其放置到指定地址。
为了实现上述效果,我们需要在 linker.ld 中定义一个段(section),并将该段放置到指定地址;在 C 代码中引用此段,在该段中定义静态数组,示例如下。
// C 代码:定义静态数组并放置到指定段
__attribute__((section(".custom_data")))
static const uint64_t npu_patterns[] = {
0x1234567890abcdef,
0xfedcba0987654321,
0xaaaaaaaaaaaaaaaa,
0x5555555555555555,
0x0011223344556677,
0x8899aabbccddeeff,
0xdeadbeefdeadbeef,
0xfeedfacefeedface
};
// linker.ld:定义自定义段并放置到指定地址
SECTIONS
{
... // 其他段定义
/* 定义自定义段 */
. = 0x30000000;
.custom_data : {
*(.custom_data)
*(.custom_data.*)
}
}